I recently got sick of opening a new tab and waiting seconds before my shell prompt showed up. In order to prevent my future self from wasting valuable seconds of my life, I went through the trouble of profiling my zsh configuration. After extensive use of zprof, I determined my bottleneck: sourcing command completion files, but only the ones that executed a program to get their contents.
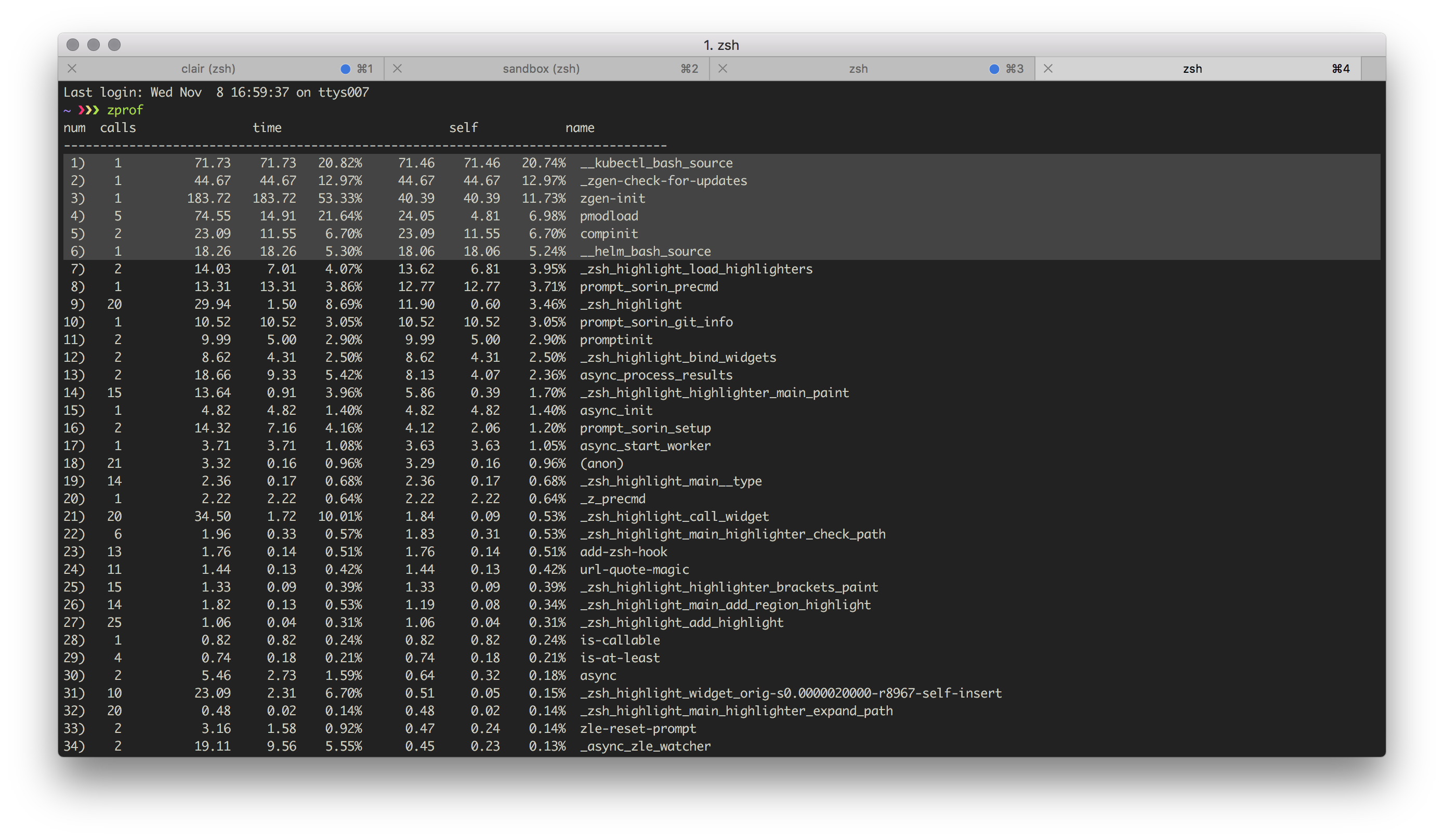
Feast your eyes on the marvel that is modern software engineering:
source <(kubectl completion zsh)
I am singling out the kubectl tool for Kubernetes, as it is a fairly common source of aggravation in my life. And while I may come off sounding extremely sardonic, I am genuinely trying to convince you that there is value in analyzing what appears to be such an insignificant snippet of shell code.
For those unfamiliar, this code snippet is intended for loading completion functions into your shell.
Completion functions are what enable users to press the tab key on their keyboard and receive text predictions for specific command-line flags and values.
In this case, the program has a command, kubectl completion zsh, that outputs the code required to teach zsh about all of the flags available from kubectl.
The source command is a built-in shell function that evaluates shell scripts.
The scary looking <() voodoo is doing nothing more than redirecting the output of the completion command into the input for the source function.
This strategy for extending users’ shells isn’t exclusive to kubectl.
At first glance, it appears to be a great way to ship shell completion files; users never have to worry that the version of the completion code and the version of the software are mismatched.
However, every design decision has trade-offs.
The performance cost of sourcing completion files is no news to the zsh developers.
Zsh has a built-in completion system that includes the caching of processed completion files into dump-files, e.g. ~/.zcompdump, such that opening future shells can avoid the overhead of reprocessing everything from scratch.
Code used for completion is usually stored as a file in directories listed in the $fpath environment variable.
Herein lies the trade-off for programs that embed their own completion files: the zsh completion system only caches completion files collected from disk. This means any tool that tells you to source their shell scripts, is unlikely to be cached and going to add significant performance overhead.
So, how do you stop tools like kubectl from destroying my shell?
Convince the software’s maintainers to package completion files with the software.
In this case, the homebrew package for kubectl actually installs a zsh completion file into a directory on the $fpath.
Rejoice, we can safely remove the hellish code snippet from our ~/.zshrc file and still tab complete kubectl.
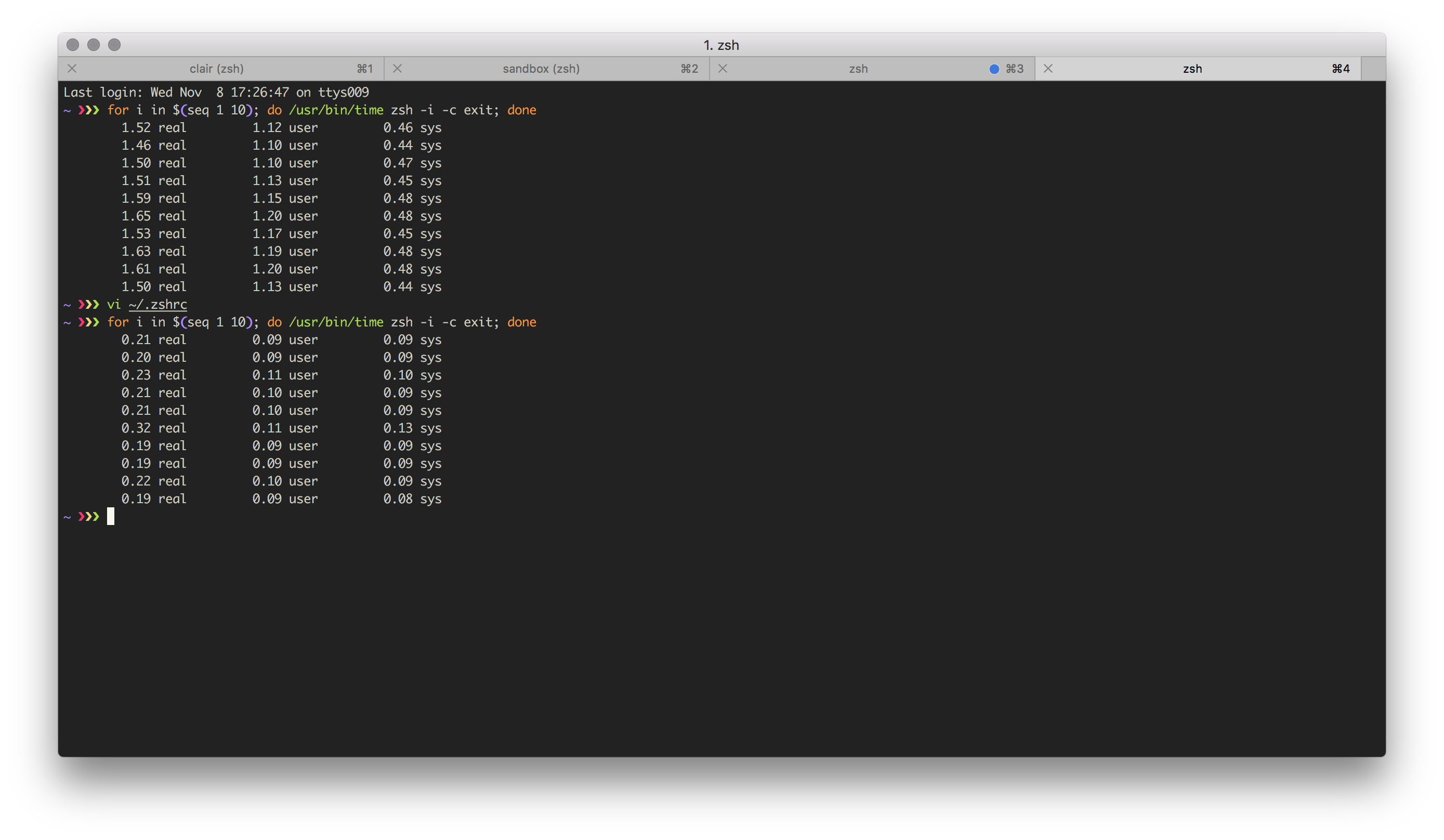
Finally, let’s compare benchmarks between my shell first sourcing a few tools, namely pyenv, kubectl, and helm, then my shell loading completion for these from cached files:
Sources / Interesting Follow-Ups:
- Of course, my zsh configuration
- The documentation on the built-in completion system
- The most performant zsh package manager, zgen
- Kevin Burke’s blog post on profiling zsh startup time.